03 · La concurrence
Ce que font Lemrock et Sumbia,
et ce qu'on fait différemment. 🎯
L
Lemrock
Widget · Console Publisher · Console Advertiser
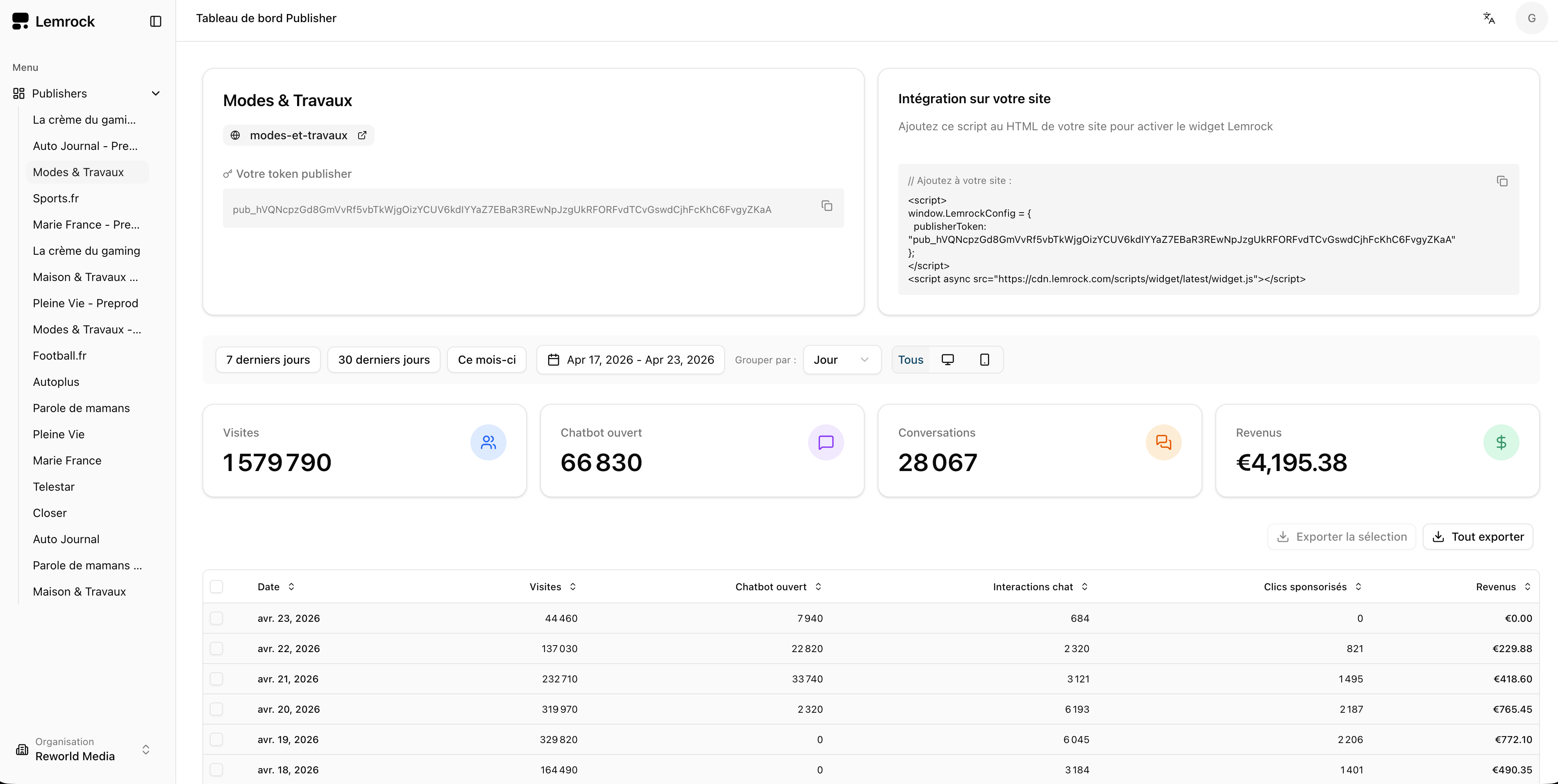
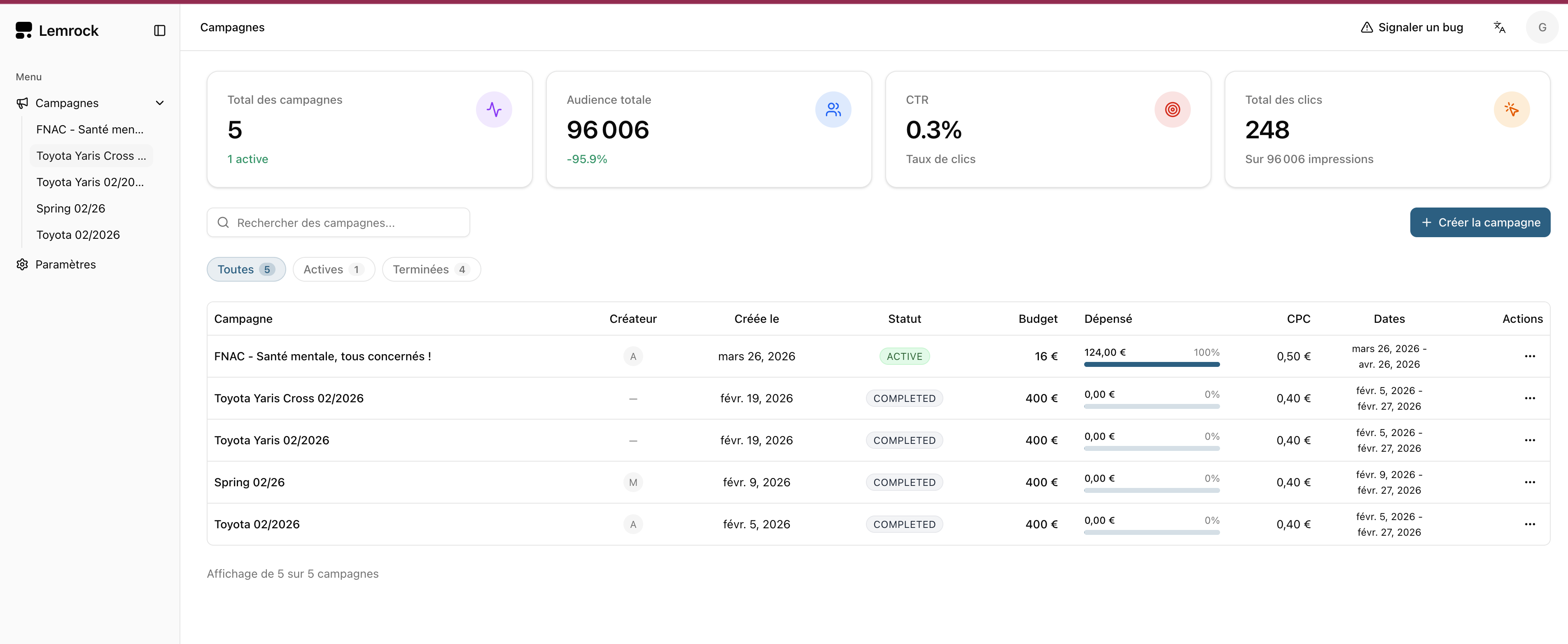
Ce qu'ils font bien. Widget chat sur article, console publisher (volumes, revenus), console advertiser (campagnes au clic, CPC, budgets, ciblage, dates).
Ce qu'on garde. La structure de campagne (budget, CPC, dates, créas) est le standard du marché.
On va plus loin — intégration RMR native et maillage cross-sites groupe.
S
Sumbia
Analytics via Grafana
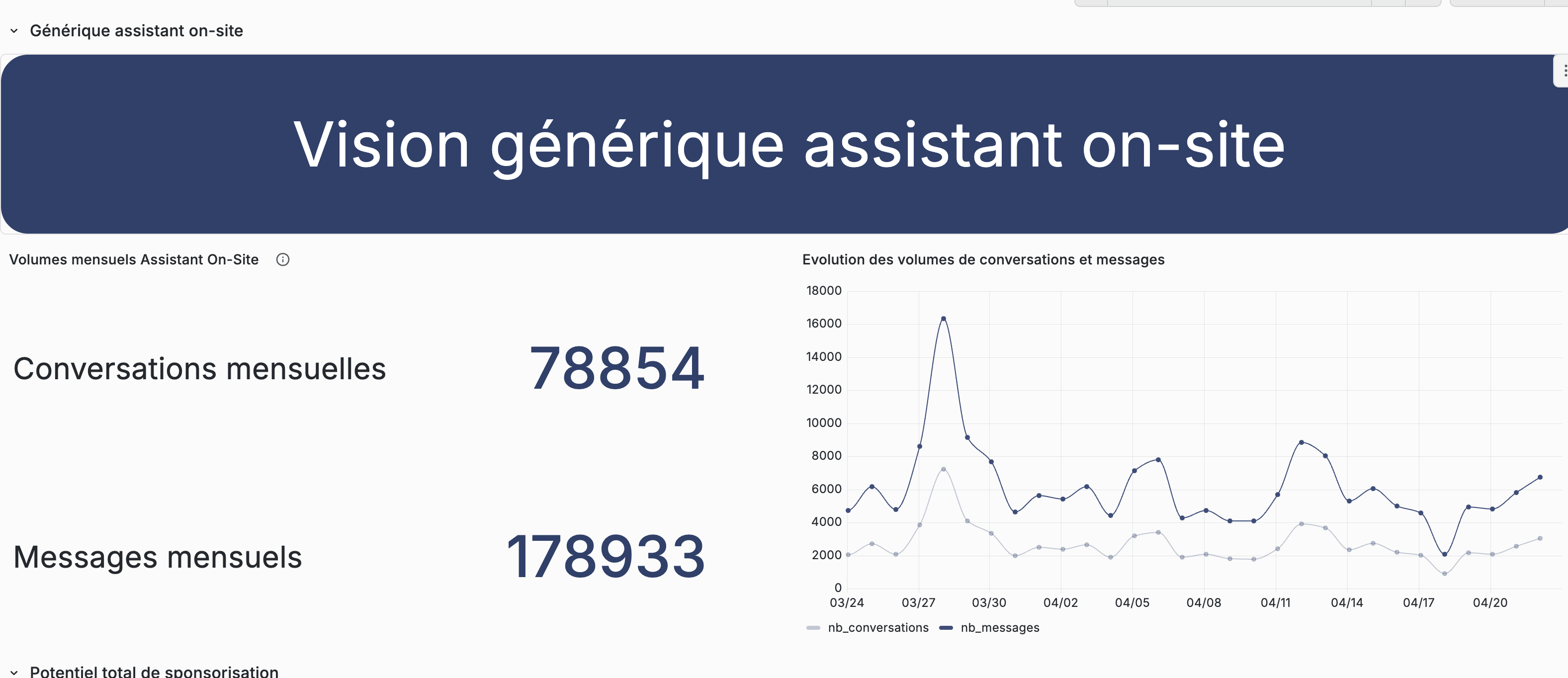
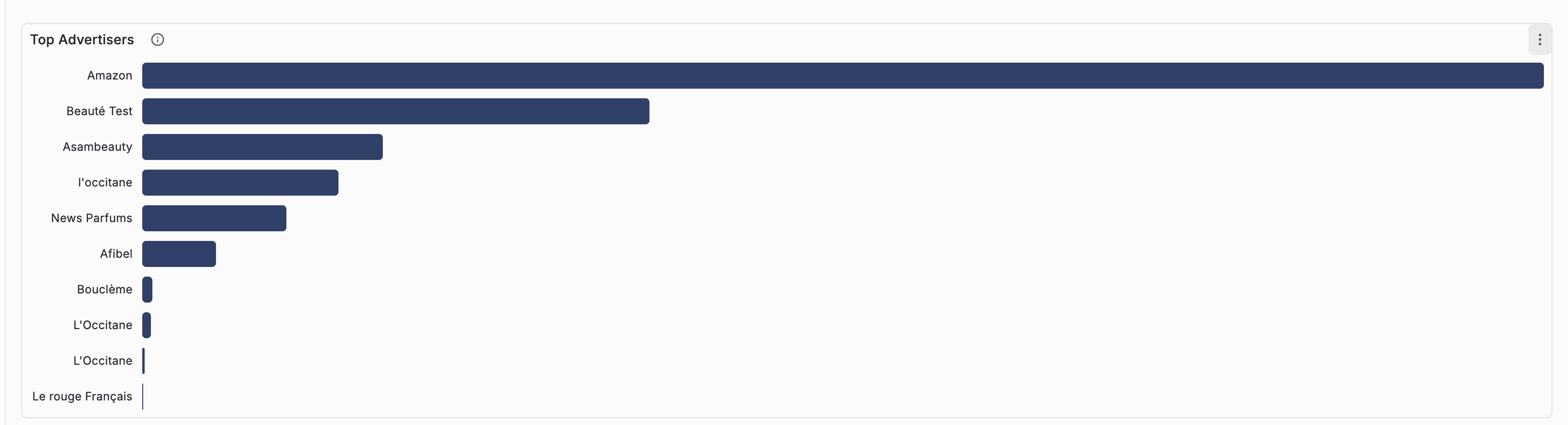
Ce qu'ils font. Analytics Grafana (conversations, messages, top produits, top advertisers) — mais en mieux, leur dashboard est horrible. Complexe, peu friendly, impossible à présenter à un annonceur.
Ce qu'on garde. La granularité des métriques. Ce qu'on refait — l'UX, de zéro, dans RMR.
On va plus loin — un cockpit propre, moderne, présentable commercialement.